



































































GPU短缺:人工智能行业的可持续发展问题

2023年8月,人工智能似乎会受到GPU供应的瓶颈。
“人工智能热潮被低估的一个原因是GPU/TPU短缺。这种短缺导致了产品推出和模型培训的各种限制,但这些都不明显。相反,我们看到的是英伟达的股价飙升。一旦供给满足需求,事情就会加速发展。”——Adam D’angelo, Quora首席执行官,Poe.com,前Facebook首席技术官
GPU是造成人工智能发展的瓶颈吗?
埃隆·马斯克表示:“在这一点上,GPU比药物要难得多。”Sam Altman说OpenAI的GPU有限的,它推迟了他们的短期计划。
小型和大型云提供商的大规模H100集群的容量正在耗尽。
“每个人都希望英伟达能生产更多的A/H100”——来自云提供商高管的消息
“我们的gpu太少了,使用我们产品的人越少越好”
“如果他们少使用我们的产品我们就会很高兴,因为我们没有足够的GPU”——Sam Altman, OpenAI的首席执行官
简而言之:是的,H100 gpu存在供应短缺。有人告诉我,对于那些需要100个或1000个H100的公司来说,Azure和GCP实际上已经没有容量了,AWS也快不行了。
这种“容量不足”是基于Nvidia给他们的分配。
GPU的供需情况,谁需要/拥有Has1000 + H100或A100
• 初创公司
OpenAI (Azure), Anthropic, Inflection (Azure与CoreWeave), Mistral AI
• CSP(云服务提供商)
三大巨头:Azure、GCP、AWS
其它公共云:Oracle
大型私有云:如CoreWeave, Lambda
• 其他大公司
Tesla
对于使用私有云的公司(CoreWeave, Lambda),拥有数百或数千H100的公司,几乎都是大型语言模型LLM,一些扩散模型可以工作。其中一些是对现有模型的微调,但大多数是你可能还不知道的新初创公司,他们正在根据H100 GPU的需求构建新模型。他们在3年内将使用几百到几千个GPU。
对于使用按需H100和少量GPU的公司来说,它仍然可能有>50%的LLM相关使用。
人们需要哪种GPU?
主要是H100s。为什么?无论是为LLM的推理还是训练,它都是最快的。(H100在推理方面的性价比也是最好的)
训练LLM最常见的需求是什么?
3.2Tb/s 无限带宽的H100。
企业LLM训练和推理的需求是什么?
对于训练,他们倾向于要H100,对于推理,更多的是关于每美元的表现。
H100和A100仍然是一个性价比问题,但H100通常更受青睐,因为它们可以使用更多的GPU进行更好的扩展,并提供更快的训练时间,并且加快/压缩启动或训练或改进模型的时间对初创公司来说至关重要。
“对于多节点培训,他们都要求配备无限带宽的A100或H100。我们只看到非A/H100请求是针对单GPU或单节点工作负载的推断。” ——私有云执行官
“H100是首选,因为它的效率高达3倍,但成本只有(1.5-2倍)。结合整体系统成本,H100每美元的性能要高得多(如果您查看系统性能,每美元的性能可能要高出4-5倍)”——深度学习研究员
市场上除了Nvidia,还有AMD,是什么原因令LLM公司不怎么使用AMD GPU?
“从理论上讲,一家公司可以购买一堆AMD的GPU,但要让所有的东西都工作起来需要时间。开发时间(即使只有2个月)可能意味着比竞争对手更晚进入市场。所以CUDA现在是英伟达的护城河。”——私有云执行官
“谁会冒险部署1万块AMD GPU或1万块随机初创公司的芯片呢?那几乎是3亿美元的投资。” ——私有云执行官
“MosaicML/MI250 -有人问过AMD的可用性吗?AMD似乎并没有为Frontier开发出他们需要的产品,现在台积电的CoWoS产能被英伟达吸走了。MI250可能是一个可行的选择,但不可获得。”——退休半导体行业专业人士
07
市场上除了Nvidia,还有AMD,是什么原因令LLM公司不怎么使用AMD GPU?
16位推理快3.5倍,16位训练快2.3倍。
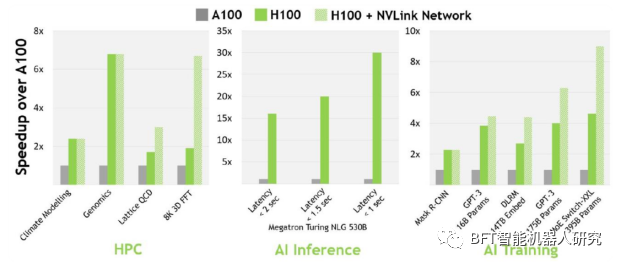
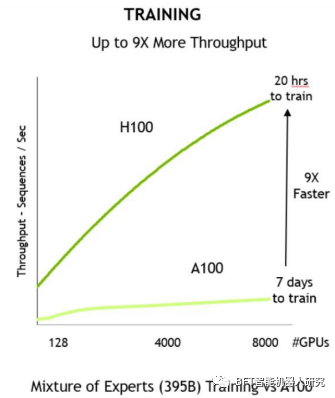
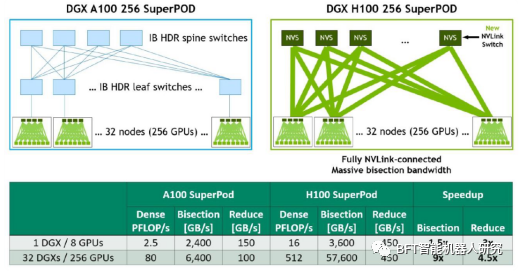
大多数人会想购买H100并将其用于训练和推理,而将他们的A100转换为主要用于推理。但是,有些人可能会因为成本、容量、使用和设置新硬件的风险以及他们现有的软件已经针对A100进行了优化而犹豫不决。
H100, GH200s, DGX GH200s, HGX H100和DGX H100之间的区别是什么?
• H100 = 1 × H100 GPU。
• HGX H100 = Nvidia服务器参考平台,oem厂商使用该平台构建4-GPU或8-GPU服务器。由美超微等第三方oem厂商制造。
• DGX H100 = Nvidia官方H100服务器,有8个H100。英伟达是唯一的供应商。
• GH200 = 1x H100 GPU + 1x Grace CPU。
• DGX GH200 = 256x GH200,到2023年底可用。可能只有英伟达提供。
这些GPU要花多少钱?
• 1x HGX H100(SXM)配备8x H100 GPU的售价在30万至38万美元之间,取决于规格(网络、存储、内存、CPU)以及销售商的利润和支持水平。
• 高端价格范围是36万至38万美元,包括支持,与DGX H100的相同规格相符。
• 1x HGX H100(PCIe)配备8x H100 GPU的售价约为30万美元,根据规格可能有所变动,包含支持。
• PCIe卡的市场价格约为3万至3.2万美元。
• SXM卡通常作为4-GPU和8-GPU服务器销售,难以给出单卡的定价。
• 大约70-80%的需求是针对SXM H100,其余部分是针对PCIe H100。
• SXM部分的需求趋势上升,因为最初几个月只有PCIe卡可用。
• 由于大多数公司购买8-GPU HGX H100s(SXM),每购买8个H100s的大致支出为36万至38万美元,包括其他服务器组件。
• DGX GH200(提醒一下,其中包含256个GH200,每个GH200包含1个H100 GPU和1个Grace CPU)的价格可能在1500万至2500万美元范围内,尽管这只是猜测,没有基于定价表。
GPU的需求数量
• GPT-4可能是在1万到2.5万块A100 GPU上进行训练的。
• Meta拥有约2.1万块A100 GPU,特斯拉拥有约7,000块A100 GPU,Stability AI拥有约5,000块A100 GPU。
• Falcon-40B模型是在384块A100 GPU上进行训练的。
• Inflection公司在其等效的GPT-3.5模型训练中使用了3,500块H100 GPU。
在供应有限的情况下,Nvidia可以纯粹地提高价格以找到一个市场均衡价格,他们在一定程度上正在这样做。但重要的是要知道,最终H100 GPU的分配取决于Nvidia更倾向于将分配权给谁。
展望与预测
英伟达透露,他们在今年下半年有更多的供应,但除此之外,他们没有透露更多,也没有量化。
“我们正在着手处理本季度的供应问题,同时我们也已经为下半年采购了大量的供应。”
“我们相信下半年我们将拥有的供应量将远远大于上半年。” ——英伟达首席财务官科莱特·克雷斯在2023年2月至4月的财报电话会议上说
什么时候会有H100的后继机型?
可能要到2024年底(2024年中期到2025年初)才会公布,这是基于英伟达在不同架构之间的历史时间。
在此之前,H100将是英伟达GPU的顶级产品。(GH200和DGX GH200不算,它们不是纯GPU,它们都使用H100作为GPU)
会有更高VRAM容量的H100 GPU吗?
也许是液冷120GB H100。
短缺何时结束?
2023年底前的产品已经售罄。
作者 | LJH
排版 | 居居手
关于BFT白芙堂机器人
BFT(白芙堂)机器人是智能机器人一站式服务平台,能为客户提供机器人选型、培训、解决方案、在线采购、本地化定制等高性价比的一站式服务。平台产品涵盖协作机器人、工业机器人、移动机器人、SCARA机器人、服务机器人、机器人夹爪、三维机器视觉设备、3D工业相机等十余种品类,实现机器人产业链产品全覆盖,并广泛应用于工业制造、实验室自动化、智慧零售、教育科研等行业。平台已与国内外知名机器人企业达成战略合作,并拥有专业的工程师团队,能为客户提供算法及系统定制、职校教学、科研实验室平台搭建、机器人展厅定制等服务,支持一对一技术支持和二次开发。










